I wanted to mention a few technologies that I've been working with and contributing to lately. This post will be pretty tech-heavy, so I'll throw out some keywords ahead of time so that you can decide if this is something that you'll be interested in reading further: WebDAV, desktop-web integration, RDF, and content-addressable storage, all in the context of my content management system of choice, Drupal.
My work specifically has been in porting and updating some work started by Arto Bendiken (whose projects, it seems, I just start to wrap my head around, and appreciate the foresightedness of, about two years after he himself conceives of them). Aside from writing a guide to his high-traffic caching module, Boost, and porting his debugging tool, Trace, to the latest version of Drupal some time ago, I've been porting his Drupal-WebDAV content bridge, File Server, fixing some bugs in the underlying DAV API, and integrating with the updated File Framework that Arto and my other colleague Miglius Alaburda have been working on.
I'll tackle each of these technologies in layers, starting from what the user sees on down to the gory details under the hood in how the files are stored and queried.
File Server
File Server lets you take a WebDAV client, such as Mac OS X's Finder or Windows Explorer or, better yet, a richer program like Transmit or Cyberduck, login to your Drupal-based website with it using the account that you already have, and drag and drop the files and folders presented there to you. Assuming your Drupal site has file nodes (essentially, chunks of content in the form of file uploads) on it, this dragging and dropping can be used to re-categorize the files, upload new files, and change your site's category structure.
Here's an example:
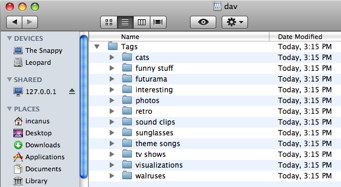
1) I have a Drupal-based website.
2) I connect to http://my-website-url/dav in a WebDAV client and login with my Drupal user credentials. I'm then presented with a view of my tags:
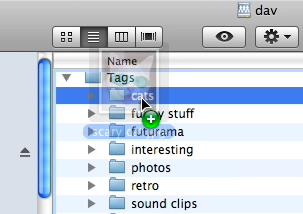
3) I drag a file from my desktop into a folder corresponding with the tag that I'd like it to be categorized under:
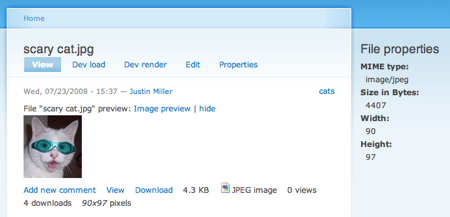
4) When I go to my Drupal site, the file exists as a node and has been tagged appropriately:
This happens via File Server, which I've recently ported to Drupal 6, and Arto's DAV API, which lets you hook all kinds of Drupal facilities into a standardized DAV interface. In this case, we're connecting Drupal's taxonomy (i.e. tags and categories) and in turn, its file nodes, to DAV. It makes a lot of sense here because the files are going into Drupal as file nodes, with automatic conversion into other formats, automatic metadata extraction (as seen in the sidebar above), and automatic indexing into the search system.
File Framework
File Framework is the link between the actual files and the node structure in Drupal. In short, File Framework takes the default facility in Drupal for file uploads and replaces it with a more robust system for backend storage, exporting of info, and conversion into alternative formats. For example, you can upload a PowerPoint presentation and automatically get related nodes out as PNG, PDF, Flash slideshow, and more.
File Framework is a lot of under-the-hood stuff and is in active development for Drupal 6. It also builds upon two other frameworks, RDF and Bitcache.
RDF
RDF stands for Resource Description Framework and is not Drupal-specific, though it embodies a concept that Drupal is trying to move towards. RDF is a step in the direction towards the semantic web, where computers can understand what data is about, not just what it contains.
The most common application for this technology is search engine technology. Today, when trying to find a picture, we search for web pages that contain the words picture of a sunset and only turn up hits if those words are found. In the semantic web, this info could be found because the search engine can understand that there is a person who has a name of Joe, who has a profession of professional photographer, and who has a website at http://joephoto.com, which in turn has a file which is a digital photograph, which has a description containing the word sunset. As a result, some context can be gleaned by the computers indexing all of this stuff, such as the fact that this likely to be a good photo of a sunset since Joe is a professional photographer, and can provide much richer info than the search engine merely looking for words that the content author may or may not have written near the object in question.
Anyway, RDF is the stuff that stores these triples, the idea of subject-predicate-object, e.g., website has a file. Arto has hacked together an API for RDF storage in Drupal and the File Framework now uses it. This RDF storage facilitates not only descriptiveness on the site, but also helps with cross-site searches when this data is needed.
None of this stuff is useful if people have to focus on creating the RDF, so this RDF API combined with Drupal makes it easy for people to keep doing what they were doing before and have the system take care of all of this context stuff.
Bitcache
Bitcache is a means for content-addressable storage (CAS), which means that, unlike most filesystems that we deal with today, the address or URL pointing to a file is based merely on the content, not on the set location. To put it another way, when you put a file on your hard drive, it gets an address like file:///users/justin/myfile.txt that is assigned arbitrarily (well, actually by you based on how you name it and where you put it, but it's arbitrarily related to the actual content). In Bitcache, a unique string of letters is calculated when the file is put into the system and as long as the content remains the same, the pointer URL to that file will remain unchanged. When the file changes, a new copy is created which necessarily has a different address; however, the old file remains in the system as well. So, a benefit is that a given file that exists in a given state is never put into the system twice, since it can be continually referred to by its content address. Another benefit is that the old versions are necessarily retained for archival purposes as well.
A quick hypothetical example: a computer server is in use by an office of people to store their MP3 collections on. When someone puts a new song on the server, it gets a content address. When a second person later puts the same song on the server, a second copy is not created -- instead, the second person gets a reference to the original file's address, since the file is the same anyway. That way, half the storage is used. As more people add the same song to their collections, the storage benefit increases. This is a simplified and contrived example, but it's the basic gist of things.
The File Framwork for Drupal makes use of Arto's Bitcache project. So, when you are using the stack of tools I've been talking about here, under it all, you also get the benefits of CAS behind the scenes.
Conclusion
I'm going to stop there, as I'm sure I've done some grave injustice to some of the complexity involved, left out some of the cons that come with the pros of these systems, and I've probably mangled some of the descriptions too. But then again, that's why I'm working on a piece of it and not the whole thing ;-)
I get excited about this stuff not just because of the Cool Factor™, but also because this sort of thing, when combined with Drupal 6's capabilities in the workflow department with triggers and actions, can lead to some powerful publishing and conversion capabilities for file uploads. And all of this paves the way for Drupal to be the most forward-thinking content management system out there.
Questions? Comments? Corrections? Leave a note below and let's sort it out.